|
|
|
|
|
Code [GitHub] |
Paper [arXiv] |
Cite [BibTeX] |
Abstract
This paper is part of the IST project, ran by PIs Anastasios Kyrillidis, Chris Jermaine, and Yingyan Lin. More info here.
|
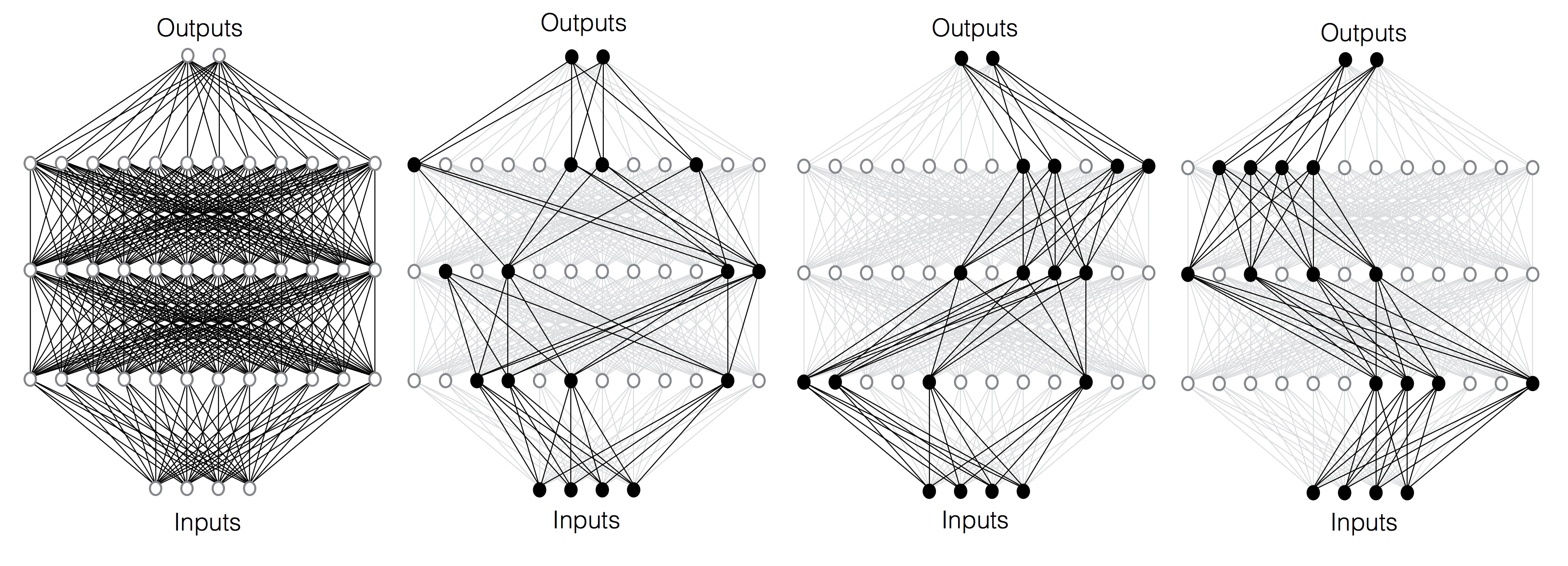
The central idea in this paper, called independent subnet training (IST), facilitates combined model and data parallel distributed training.
IST utilizes ideas from dropout and approximate matrix multiplication.
IST decomposes the NN layers into a set of subnets for the same task, by partitioning the neurons across different sites.
Each of those subnets is trained for one or more local stochastic gradient descent (SGD) iterations, before synchronization. Since subnets share no parameters in the distributed setting, synchronization requires no aggregation on these parameters, in contrast to the data parallel method---it is just an exchange of parameters. Moreover, because subnets are sampled without replacement, the interdependence among them is minimized, which allows their local SGD updates for a larger number of iterations without significant ``model drifting'', before synchronizing. This reduces communication frequency. Communication costs per synchronization step are also reduced because in an n-machine cluster, each machine gets between 1/n^2 and 1/n of the weights---contrast this to data parallel training, when each machine must receive all of the weights. IST has advantages over model parallel approaches. Since subnets are trained independently during local updates, no synchronization between subnetworks is required. Yet, IST inherits the advantages of model parallel methods. Since each machine gets just a small fraction of the overall model, IST allows the training of very large models that cannot fit into the RAM of a node or a device. This can be an advantage when training large models using GPUs, which tend to have limited memory. Contributions.This paper has the following key contributions:
|
|
Learning tasks and environments:
We train Google speech and Resnet18 on CIFAR10 on three AWS CPU clusters, with 2, 4, and 8 CPU instances (m5.2xlarge). We train the VGG model on full ImageNet and Amazon-670k extreme classification network on three AWS GPU clusters, with 2, 4, and 8 GPU machines (p3.2xlarge). Our choice of AWS was deliberate, as it is a very common learning platform, and illustrates the challenge faced by many consumers: distributed ML without a super-fast interconnect. |
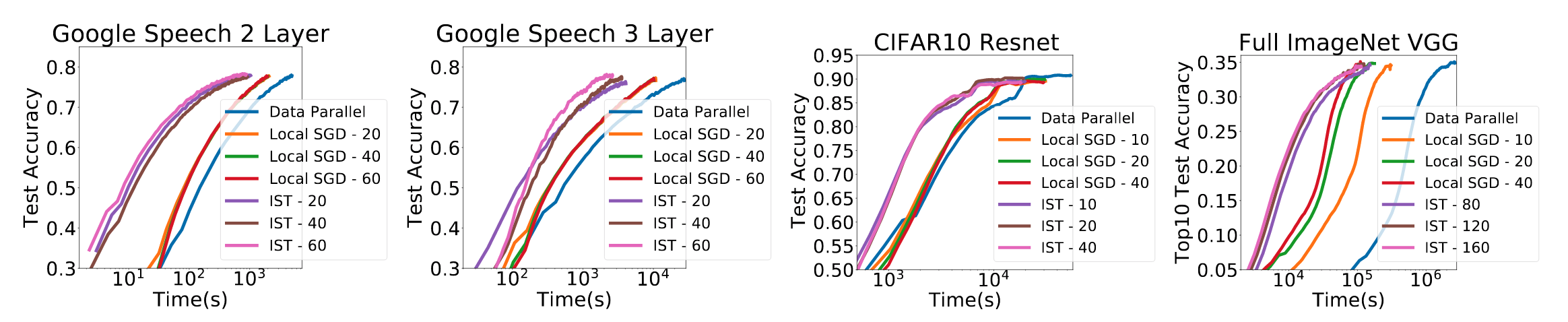
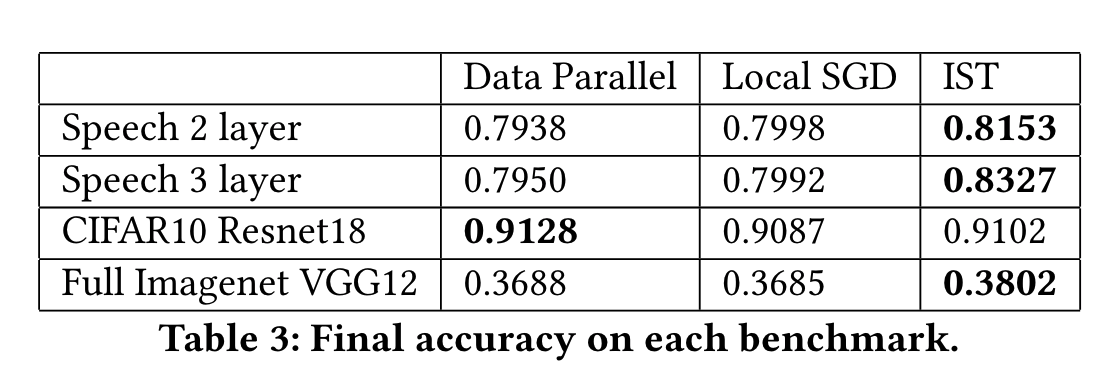
The figure and the table above generally show that IST is much faster compared to the other frameworks for achieving high levels of accuracy on a hold-out test set. For example, IST exhibits a 4.2x speedup compared to local SGD, and 10.6x speedup compared to classical data parallel for the 2-layer Google speech model to reach 77%. IST exhibits 6.1x speedup compared to local SGD, and a 16.6x speedup comparing to data parallel for the 3-layer model to reach the accuracy of 77%. Note that this was observed even though IST was handicapped by its use of gloo for its GPU implementation. Interestingly, for the full ImageNet data set, the communication bottleneck using AWS is so severe that the smaller clusters were always faster; at each cluster size, IST was still the fastest option. For CIFAR10, because CPUs were used for training, the network is less of a bottlneck and all methods were able to scale. This negates the IST advantage just a bit. In this case, IST was fastest to 85% accuracy, but was slower to fine-tune to 90% accuracy in 8-CPU cluster.
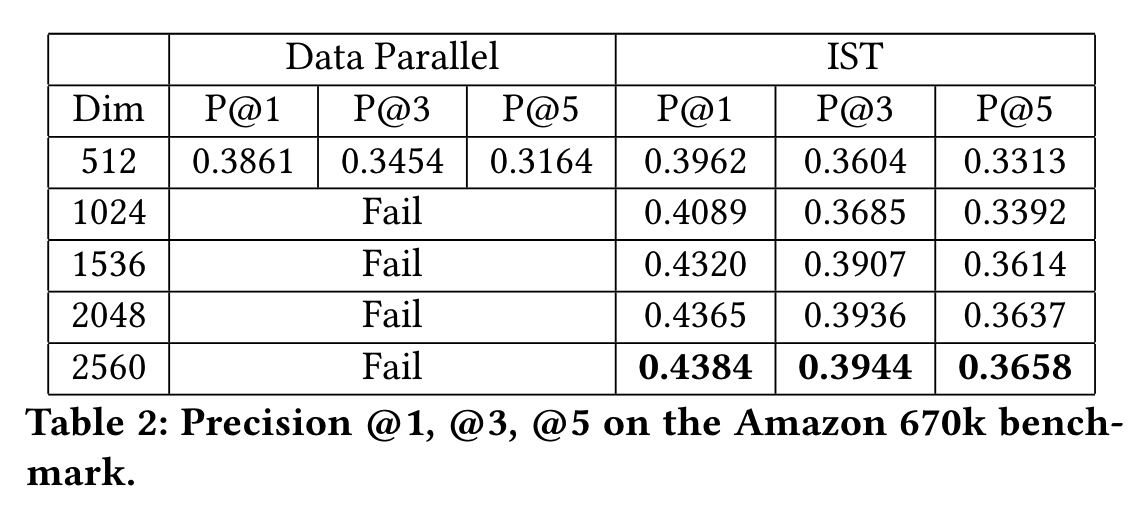
Another key advantage of IST is illustrated in the table above; because it is a model-parallel framework and distributes the model to multiple machines, IST is able to scale to virtually unlimited model sizes. In this case, it can compute 2560-dimensional embedding in 8-GPU cluster (and realize the associated, additional accuracy) whereas the data parallel approaches are unable to do this.
Acknowledgements |