Independent Subnetwork Training
Supported by NSF/Intel (CNS 2003137)
Collaborators:Anastasios Kyrillidis (Rice CS - PI)
Chris Jermaine (Rice CS - PI)
Yingyan Lin (Rice ECE - PI)
Students:
Chen Dun (Rice CS), Cameron R. Wolfe (Rice CS), Jasper Liao (Rice CS), Chuck Wang (Rice CS)
Neural networks (NN) are ubiquitous, and have led to the recent success of machine learning (ML). For many applications, model training and inference need to be carried out in a timely fashion on a computation-/communication-light, and energy-limited platform. Optimizing the NN training in terms of computation/com- munication/energy efficiency, while retaining competitive accuracy, has become a fundamental challenge.
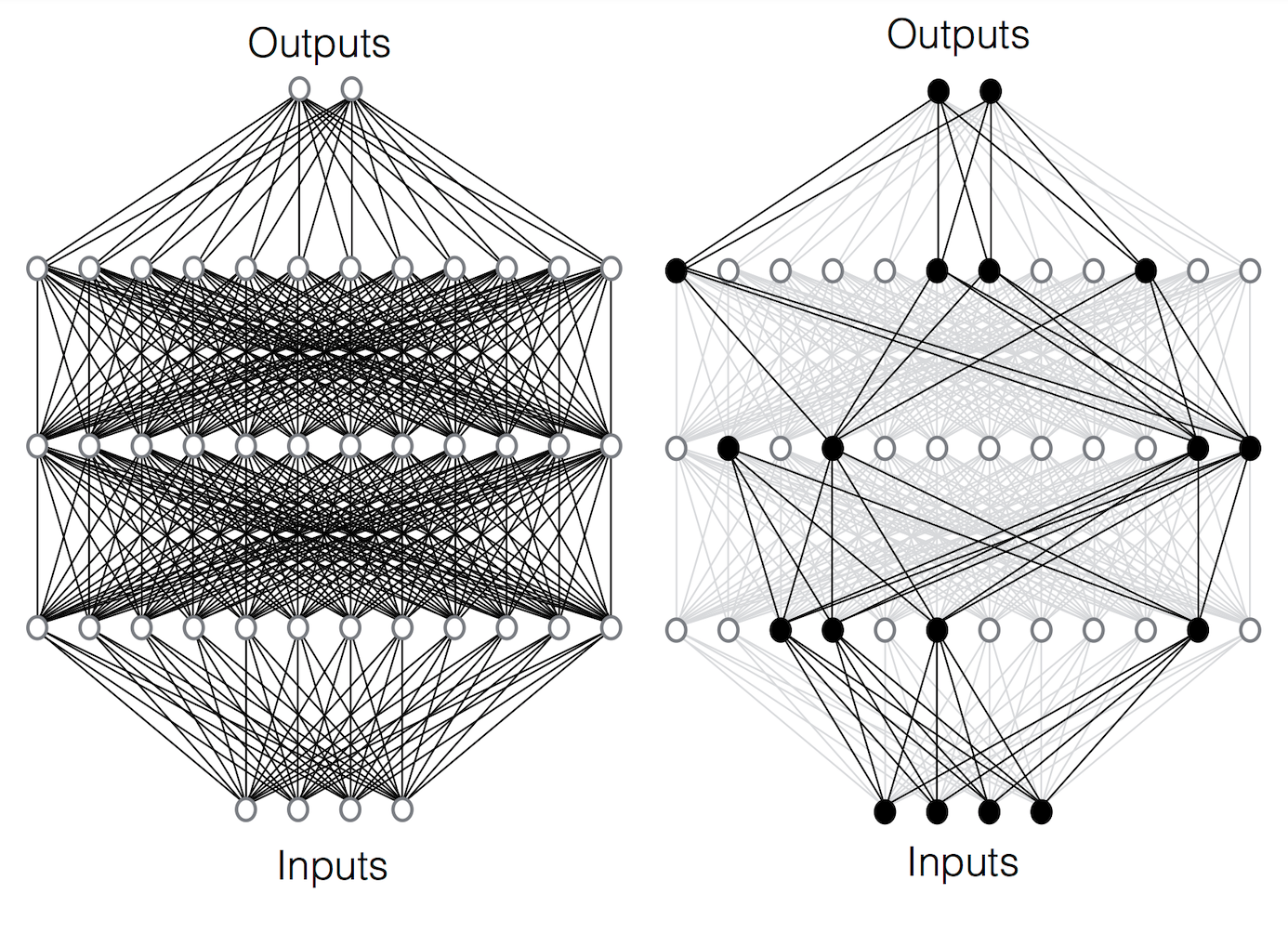
We propose a new class of neural network (NN) training algorithms, called independent subetwork training (IST). IST decomposes the NN into a set of independent subnetworks. Each of those subnetworks is trained at a different device, for one or more backpropagation steps, before a synchronization step. Updated subnetworks are sent from edge-devices to the parameter server for reassembly into the original NN, before the next round of decomposition and local training. Because the subnetworks share no parameters, synchronization requires no aggregation; it is just an exchange of parameters. Moreover, each of the subnetworks is a fully-operational classifier by itself; no synchronization pipelines between subnetworks are required. Key attributes of our proposal is that \(i)\) decomposing a NN into more subnetworks means that each device receives fewer parameters, as well as reduces the cost of the synchronization step, and \(ii)\) each device trains a much smaller model, resulting in less computational costs and better energy consumption. Thus, there is good reason to expect that IST will scale much better than a “data parallel” algorithm for mobile applications.
Results by this projects include:
- Distributed Learning of Deep Neural Networks using Independent Subnet Training.
- GIST: Distributed Training for Large-Scale Graph Convolutional Networks.
- ResIST: Layer-Wise Decomposition of ResNets for Distributed Training.
- On the Convergence of Shallow Neural Network Training with Randomly Masked Neurons
- LOFT: Finding Lottery Tickets through Filter-wise Training
- Efficient and Light-Weight Federated Learning via Asynchronous Distributed Dropout
Some works that came after this line of work:
- PruneFL
- Helios
- HeteroFL
- FjORD - Samsung
- PVT - Google
- Masked NNs
- Further theory on masked NNs
- Federated dropout - LG
- Federated dropout - Google
- Federated pruning - Google
- FedSelect - Google
- FedRolex - Google (among others)
Publications
Binhang Yuan, Cameron R. Wolfe, Chen Dun, Yuxin Tang, Anastasios Kyrillidis, Christopher M. Jermaine, ``Distributed Learning of Deep Neural Networks using Independent Subnet Training’‘, Proceedings of the VLDB Endowment, Volume 15, Issue 8, April 2022, pp 1581–1590, https://doi.org/10.14778/3529337.3529343.
Cameron R. Wolfe, Jingkang Yang, Arindam Chowdhury, Chen Dun, Artun Bayer, Santiago Segarra, Anastasios Kyrillidis, '’GIST: Distributed Training for Large-Scale Graph Convolutional Networks’‘, Arxiv Preprint, submitted Springer special issue on Data Science and Graph Applications.
Chen Dun, Cameron R. Wolfe, Christopher M. Jermaine, Anastasios Kyrillidis, '’ResIST: Layer-wise decomposition of ResNets for distributed training’‘, Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence, PMLR 180:610-620, 2022.
Fangshuo (Jasper) Liao, Anastasios Kyrillidis, '’On the convergence of shallow neural network training with randomly masked neurons’‘, Transactions on Machine Learning Research, 2022.
Qihan Wang, Chen Dun, Fangshuo (Jasper) Liao*, Chris Jermaine, Anastasios Kyrillidis, '’LOFT: Finding Lottery Tickets through Filter-wise Training’‘, arXiv preprint arXiv:2210.16169, 2022.
Chen Dun, Mirian Hipolito, Chris Jermaine, Dimitrios Dimitriadis, Anastasios Kyrillidis, '’Efficient and Light-Weight Federated Learning via Asynchronous Distributed Dropout’‘, arXiv preprint arXiv:2210.16105, 2022.