|
|
|
Code [GitHub] |
Paper [arXiv] |
Cite [BibTeX] |
Abstract
This paper is part of the IST project, ran by PIs Anastasios Kyrillidis, Chris Jermaine, and Yingyan Lin. More info here.
|
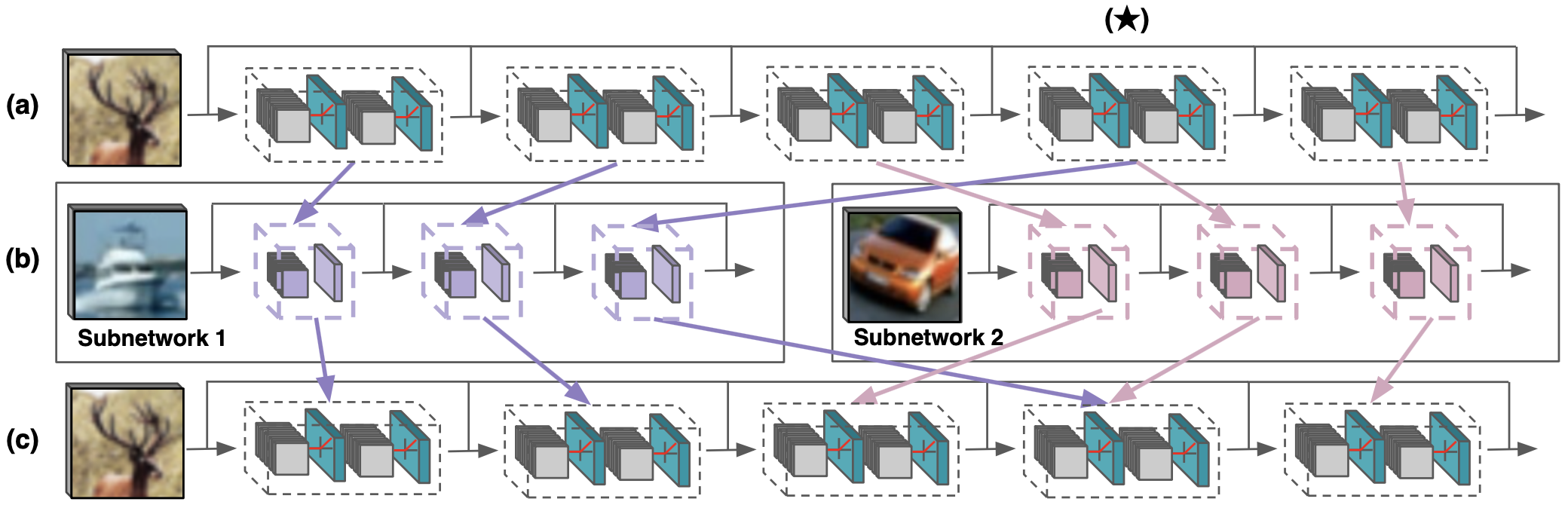
ResIST operates by partitioning the layers of a global ResNet to different, shallower sub-ResNets, training those independently, and intermittently aggregating their updates into the global model. The high-level process followed by ResIST is depicted in the figure above.
As shown in the transition from row (a) to (b) within the above figure, indices of partitioned layers within the global model are randomly permuted and distributed to sub-ResNets in a round-robin fashion. Each sub-ResNet receives an equal number of convolutional blocks (e.g., see row (b)). In certain cases, residual blocks may be simultaneously partitioned to multiple sub-ResNets to ensure sufficient depth (e.g., see block 4 in the figure). ResIST produces subnetworks with 1/S of the global model depth, where S represents the number of independently-trained sub-ResNets. The shallow sub-ResNets created by ResIST accelerate training and reduce communication in comparison to methods that communicate and train the full model. After constructing the sub-ResNets, they are trained independently in a distributed manner (i.e., each on separate GPUs with different batches of data) for l iterations. Following independent training, the updates from each sub-ResNet are aggregated into the global model. Aggregation sets each global network parameter to its average value across the sub-ResNets to which it was partitioned. If a parameter is only partitioned to a single sub-ResNet, aggregation simplifies to copying the parameter into the global model. After aggregation, layers from the global model are re-partitioned randomly to create a new group of sub-ResNets, and this entire process is repeated. Contributions.This paper has the following key contributions:
|
|
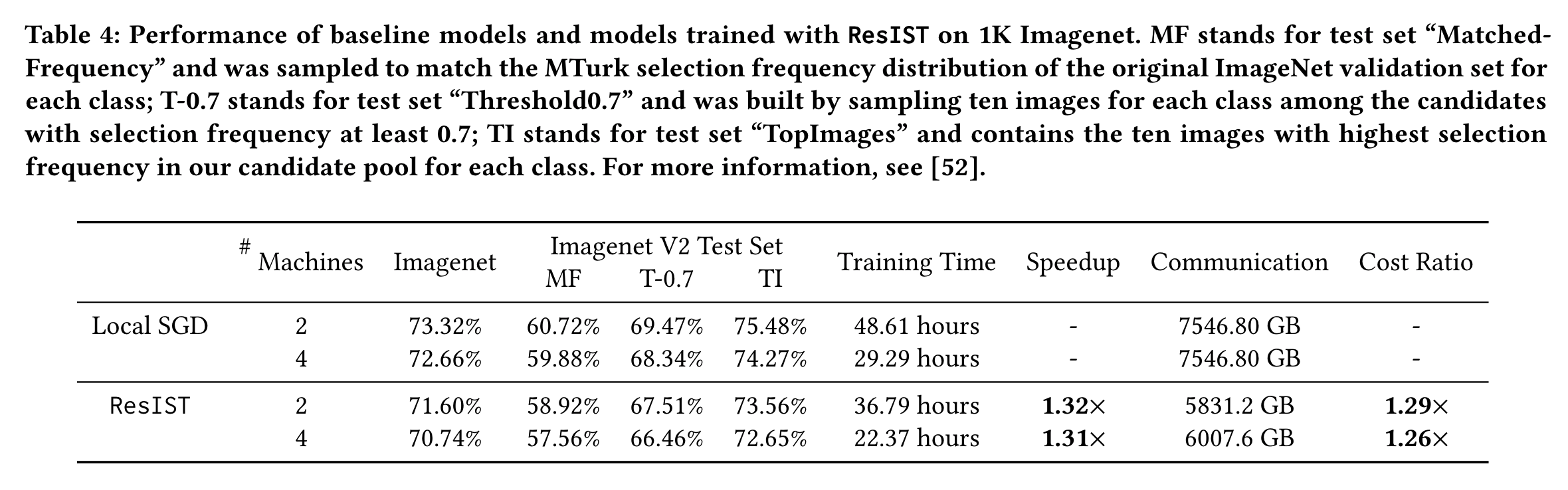
Accuracy: The test accuracy of models trained with both ResIST and local SGD for different numbers of machines on the ImageNet dataset is listed in the table below. As can be seen, ResIST achieves comparable test accuracy (<2% difference) to local SGD in all cases where the same number of machines are used. As many current image classification models overfit to the ImageNet test set and cannot generalize well to new data, models trained with both local SGD and ResIST are also evaluated on three different Imagenet V2 testing sets. As shown in the table below, ResIST consistently achieves comparable test accuracy in comparison to local SGD on these supplemental test sets. |
|
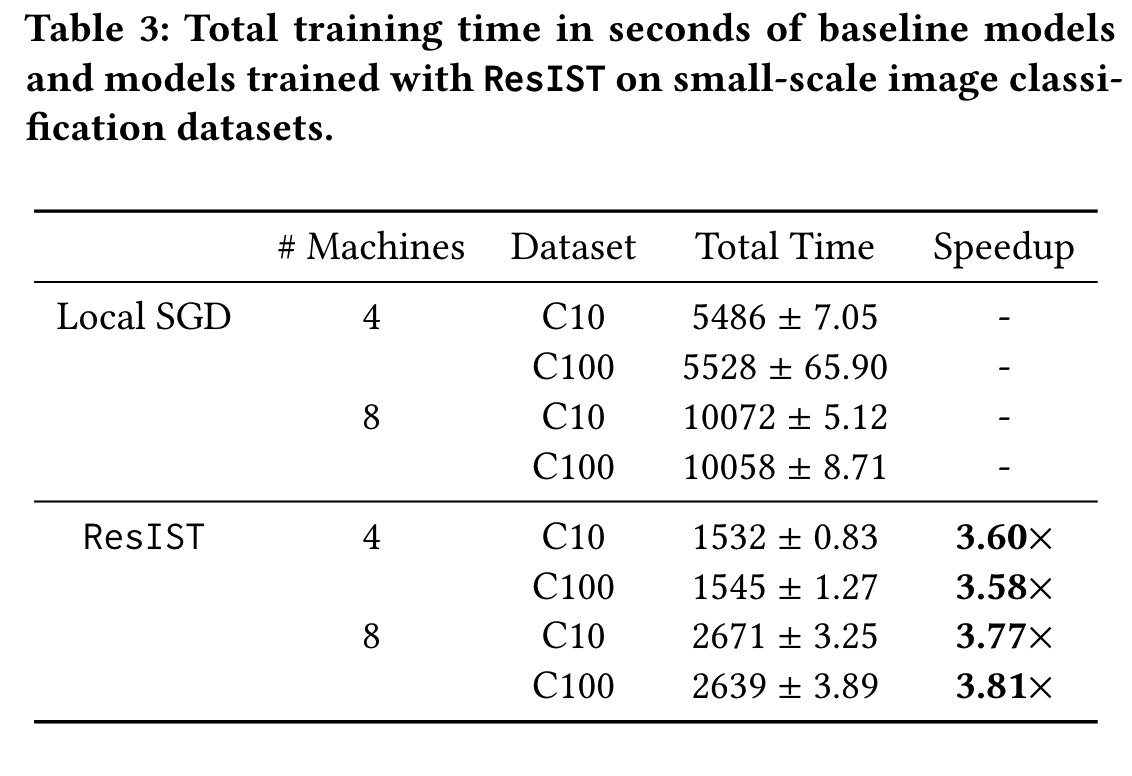
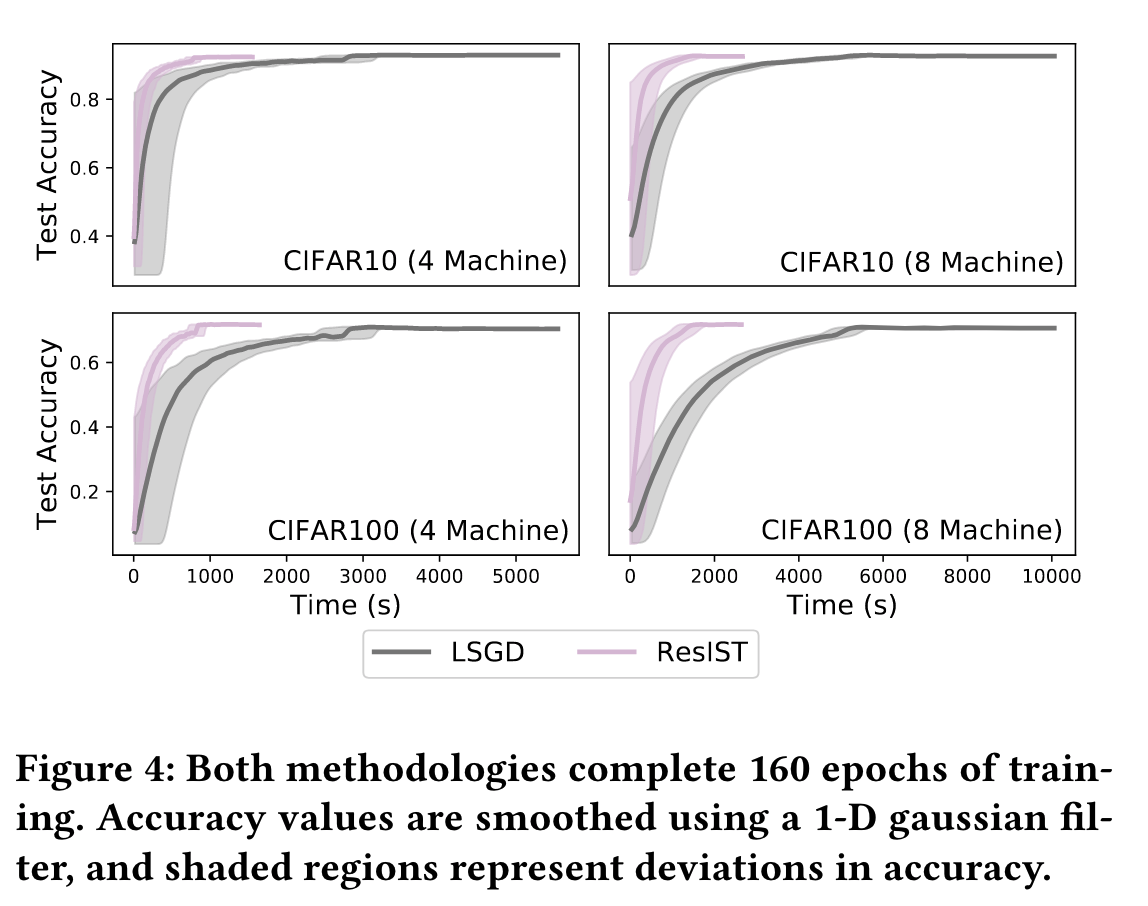
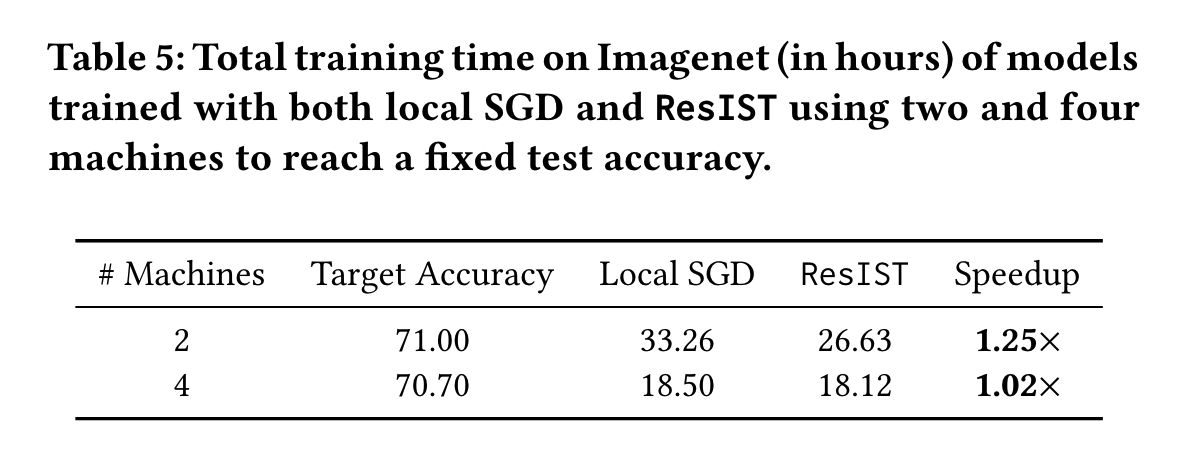
Efficiency: In addition to achieving comparable test accuracy to local SGD, ResIST significantly accelerates training. This acceleration is due to i) fewer parameters being communicated between machines and ii) locally-trained sub-ResNets being shallower than the global model. Wall-clock training times for four and eight machine experiments are presented in the table above. ResIST provides 3.58x to 3.81x speedup in comparison to local SGD. For eight machine experiments, a significant speedup over four machine experiments is not observed due to the minimum depth requirement and a reduction in the number of local iterations to improve training stability. We conjecture that for cases with higher communication cost at each synchronization and a similar number of synchronizations, eight worker ResIST could lead to more significant speedups in comparison to the four worker case. A visualization of the speedup provided by ResIST on the CIFAR10 and CIFAR100 datasets is illustrated in the figure below. From these experiments, it is clear that the communication-efficiency of ResIST allows the benefit of more devices to be better realized in the distributed setting. |
Large-scale Image classification
|
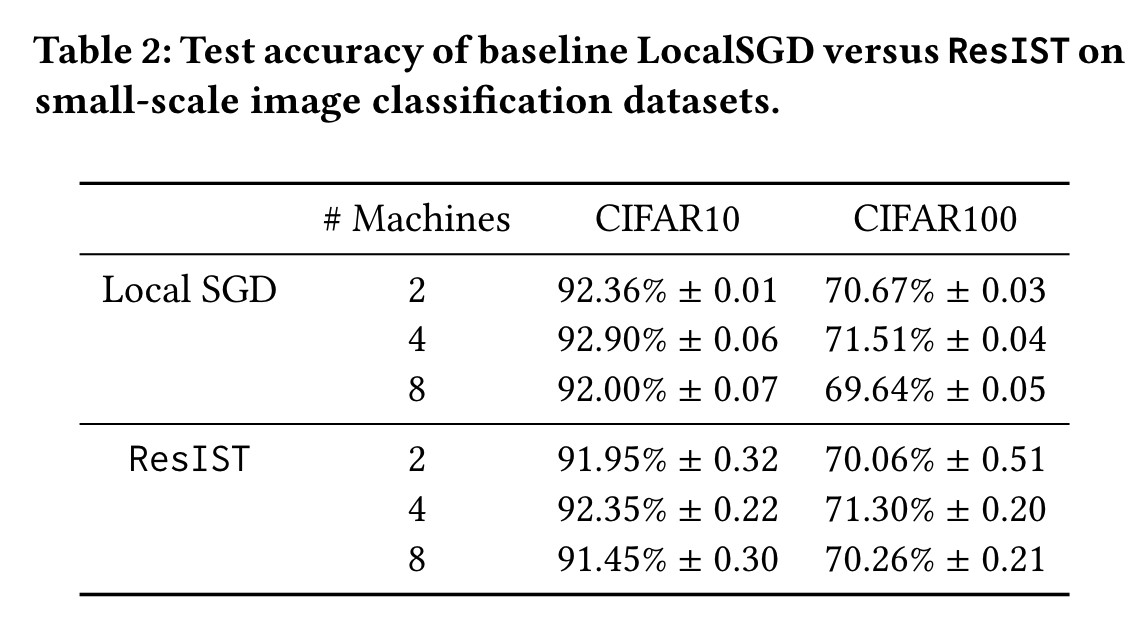
Accuracy: The test accuracy of models trained with both ResIST and local SGD on small-scale image classification datasets is listed in the table above. ResIST achieves comparable test accuracy in all cases where the same number of machines are used. Additionally, ResIST outperforms localSGD on CIFAR100 experiments with eight machines. The performance of ResIST and local SGD are strikingly similar in terms of test accuracy. In fact, the performance gap between the two method does not exceed 1% in any experimental setting. Furthermore, ResIST performance remains stable as the number of sub-ResNets increases, allowing greater acceleration to be achieved without degraded performance (e.g., see CIFAR100 results). Generally, using four sub-ResNets yields the best performance with **ResIST. |
|
Efficiency: ResIST significantly accelerates the ImageNet training process. However, due to the use of fewer local iterations and the local SGD warm-up phase, the speedup provided by ResIST is smaller relative to experiments on small-scale datasets. In the table above, ResIST can reduce the total communication volume during training, which is an important feature in the implementation of distributed systems with high computational costs. |
Acknowledgements |