
Github available software packages
-
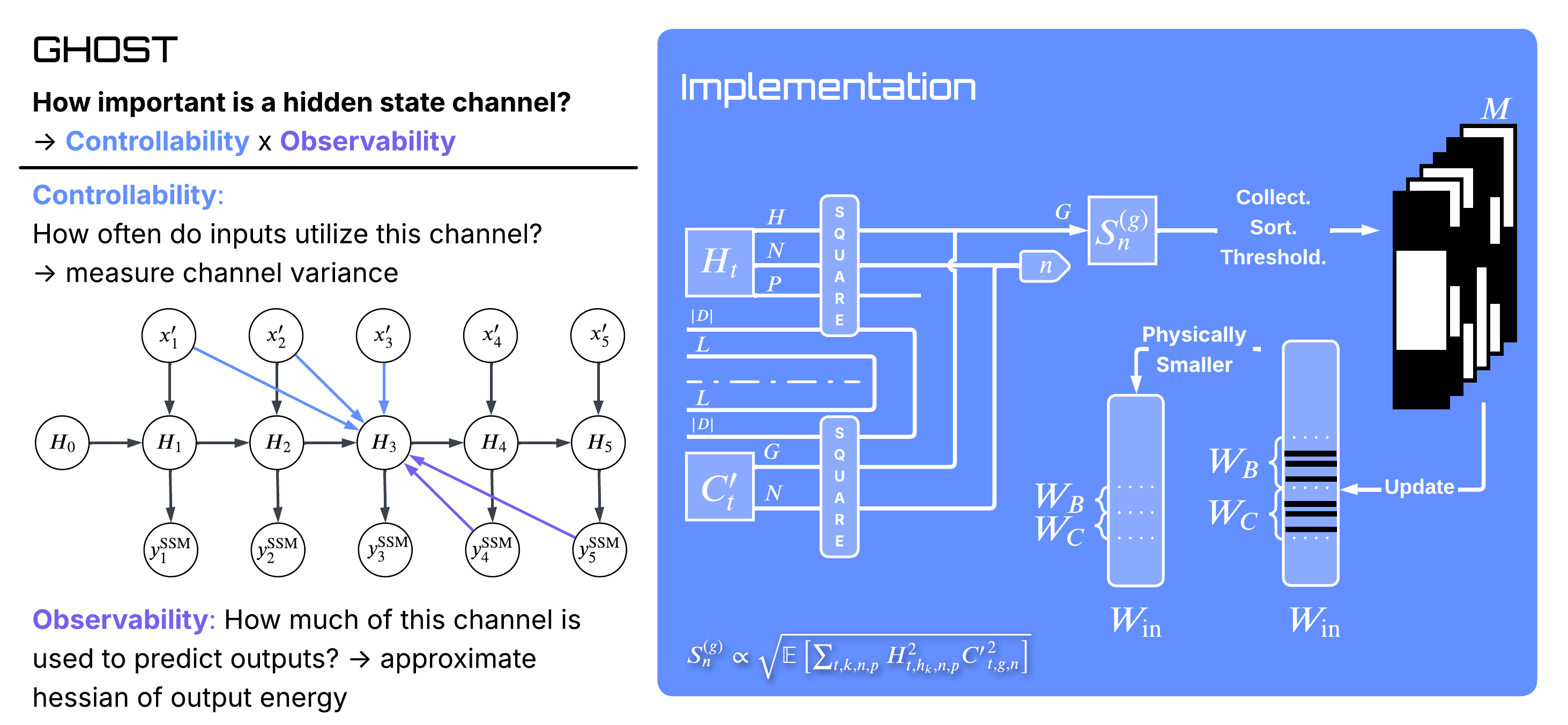
GHOST: Grouped Hidden-state Output-aware Selection and Truncation — State Pruning for Mamba2 Selective State-Space Models (Python/PyTorch)
Michael Menezes, Anastasios Kyrillidis. ICML 2026 (Seoul).
While Mamba2's expanded state dimension enhances temporal modeling, it incurs substantial inference overhead that saturates bandwidth during autoregressive generation. Standard pruning methods fail to address this bottleneck: unstructured sparsity leaves activations dense, magnitude-based selection ignores runtime dynamics, and gradient-based methods impose prohibitive costs. We introduce GHOST (Grouped Hidden-state Output-aware Selection and Truncation), a structured pruning framework that approximates control-theoretic balanced truncation using only forward-pass statistics. By jointly measuring controllability and observability, GHOST rivals the fidelity of gradient-based methods without requiring backpropagation. On models ranging from 130M to 2.7B parameters, our approach achieves a 50% state-dimension reduction with approximately 1 perplexity point increase on WikiText-2.
-
Stochastic Self-Stabilization at the Edge of Stability (Python/PyTorch)
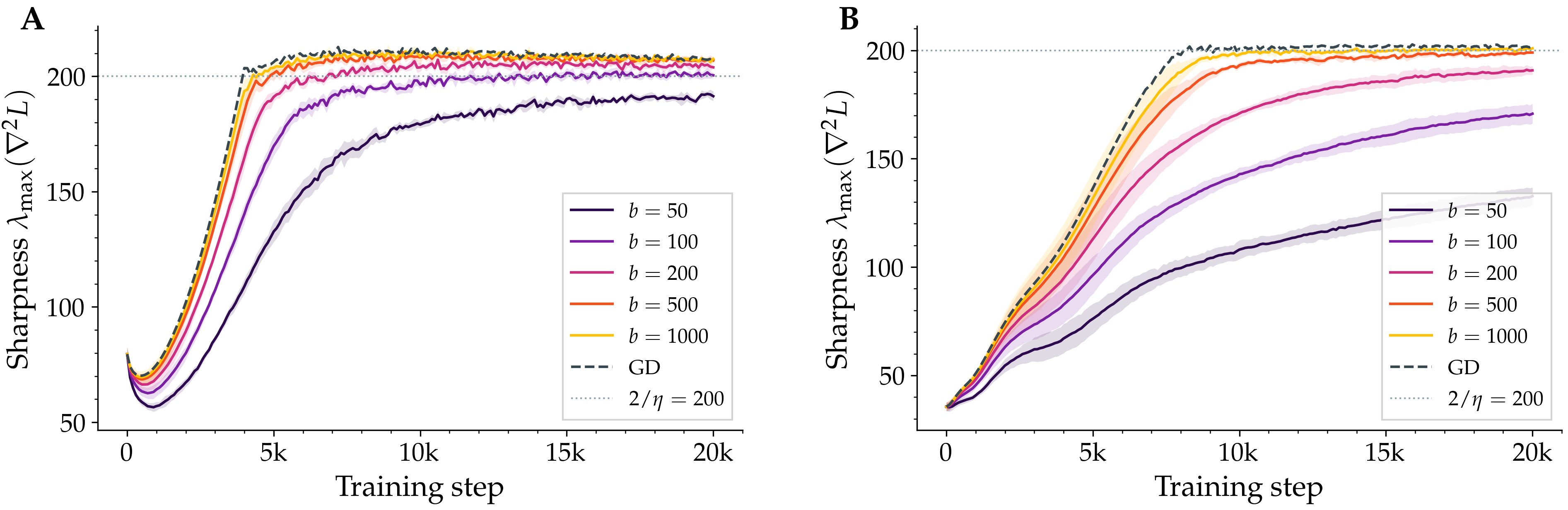
Fangshuo (Jasper) Liao, Afroditi Kolomvaki, Anastasios Kyrillidis.
Train a neural network with full-batch gradient descent and the largest eigenvalue of its loss Hessian — the sharpness — climbs to a specific value, 2/η, and pins itself there: the well-known Edge of Stability. Replace gradient descent with mini-batch SGD and the same quantity sits below 2/η, with the gap widening as the batch shrinks. We close this. Our analysis extends Damian's coupling theorem to the stochastic case and yields a closed-form sharpness gap ΔS ≈ (ηβσu2)/(4α), inversely proportional to batch size and depending on three landscape quantities — progressive sharpening rate α, self-stabilisation strength β, and the noise variance projected onto the top Hessian eigenvector. Experiments on CIFAR-10 confirm the 1/b scaling (fitted slope −1.27, R2 = 0.98) across MLP and small-CNN architectures.
-
Multiplicative Gaussian Input Noise for Two-Layer ReLU Networks (Python/PyTorch)
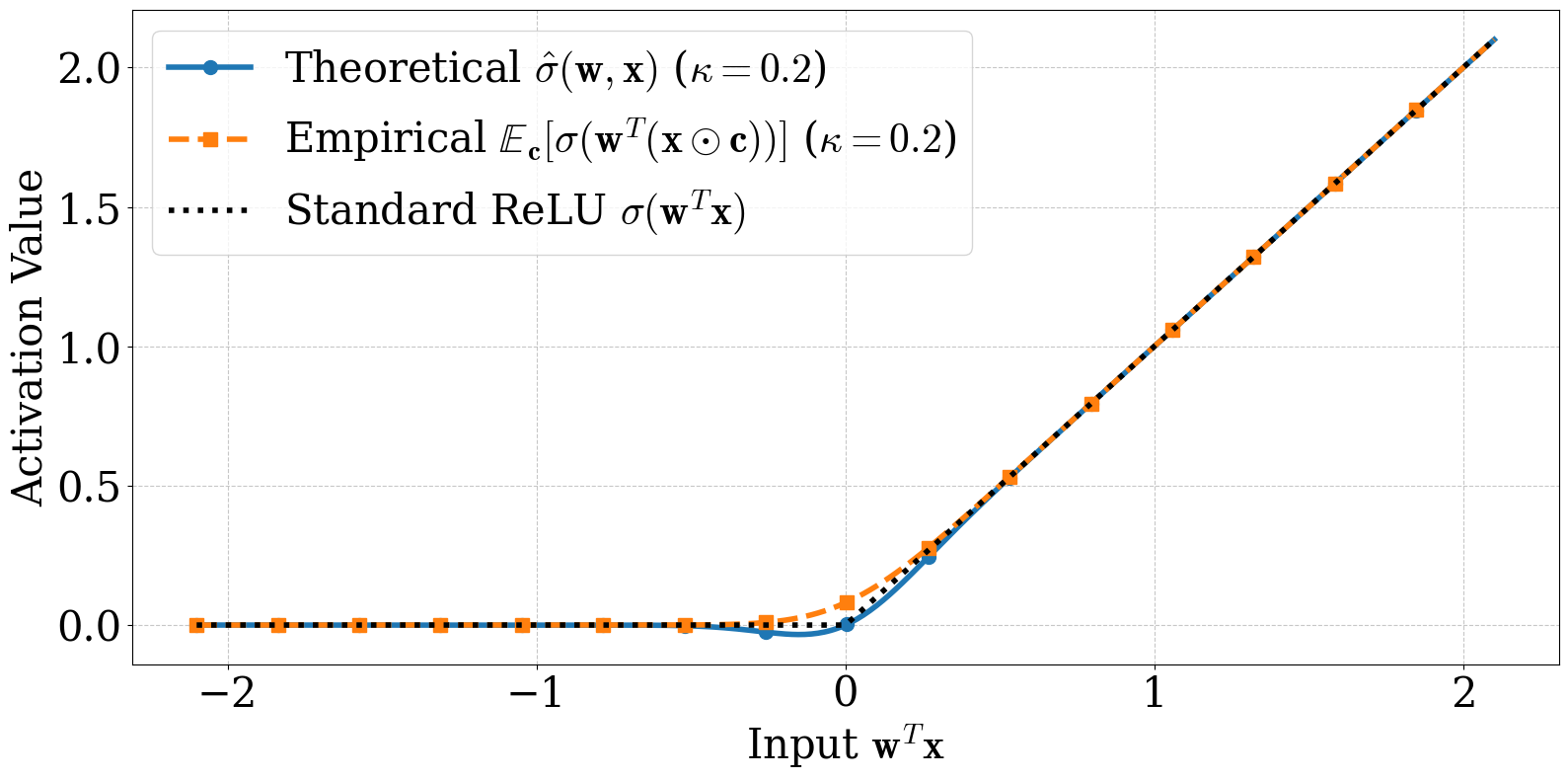
Afroditi Kolomvaki, Fangshuo (Jasper) Liao, Evan Dramko, Ziyun Guang, Anastasios Kyrillidis.
What happens when every input to a two-layer ReLU network is multiplied by an independent Gaussian random number — centered at 1, standard deviation κ, with a fresh draw at every iteration? The training loss does not blow up: it converges linearly to a target whose distance from the global minimum we can write down as a function of κ, the network width m, and the number of samples n. The technical move is a closed-form expectation: when the argument of a ReLU is Gaussian, the expected output has a clean expression z·Φ(z/σ) + σ·φ(z/σ). Plugged back into the loss, the expected loss decomposes into a smoothed-network MSE plus a κ2-scaled regularizer, both clean enough to admit an NTK-style convergence proof. Underneath the result is a general SGD theorem for biased gradient estimators with a relaxed smoothness condition.
-
Exploiting Low-Rank Structure in Max-K-Cut Problems (Python/PyTorch)

Ria Stevens, Fangshuo Liao, Barbara Su, Jianqiang Li, Anastasios Kyrillidis
We approach the Max-3-Cut problem through the lens of maximizing complex-valued quadratic forms and demonstrate that low-rank structure in the objective matrix can be exploited, leading to alternative algorithms to classical semidefinite programming (SDP) relaxations and heuristic techniques. We propose an algorithm for maximizing these quadratic forms over a domain of size K that enumerates and evaluates a set of O(n2r−1) candidate solutions, where n is the dimension of the matrix and r represents the rank of an approximation of the objective. We prove that this candidate set is guaranteed to include the exact maximizer when K=3 (corresponding to Max-3-Cut) and the objective is low-rank, and provide approximation guarantees when the objective is a perturbation of a low-rank matrix. This construction results in a family of novel, inherently parallelizable and theoretically-motivated algorithms for Max-3-Cut. Extensive experimental results demonstrate that our approach achieves performance comparable to existing algorithms across a wide range of graphs, while being highly scalable.
-
Provable Model-Parallel Distributed PCA with Parallel Deflation (Python/PyTorch)
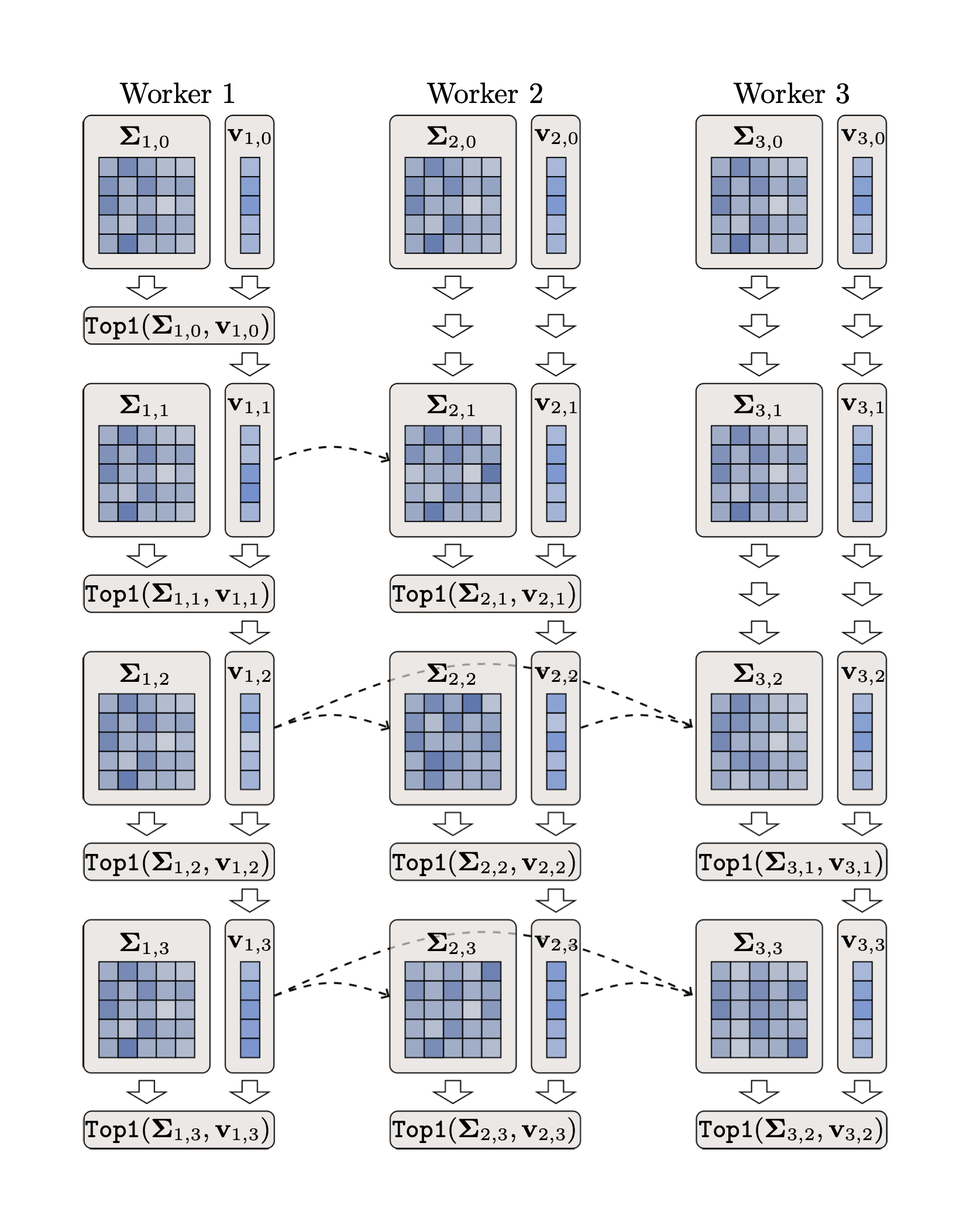
Fangshuo (Jasper) Liao, Wenyi Su, Anastasios Kyrillidis. CPAL 2025.
We introduce Parallel Deflation, a distributed PCA framework where K workers compute all K principal components simultaneously, with no sequential dependencies. Unlike prior approaches that require components to be extracted one at a time, our method provides the first provable convergence guarantees for model-parallel PCA: each component converges at a geometric rate that depends on the spectral gap, and crucially, errors from early imprecise estimates self-correct as later components improve. The algorithm achieves substantial speedups over sequential deflation while maintaining theoretical optimality, with applications including LoRA fine-tuning and large-scale matrix factorization.
Code packages (before moving to Github)
-
(Bi-) Factored Gradient Descent algorithm for low-rank recovery (Matlab)
This software package is a proof of concept for $UV^\top$ parameterization in optimization and focuses on first-order, gradient descent algorithmic solutions for the case of matrix sensing. The algorithm proposed is named as Bi-Factored Gradient Descent (BFGD) algorithm, an efficient first-order method that operates on the $U, V$ factors. Subsequent versions will include more involved applications such as 1-bit matrix completion (logistic regression objective), low-rank image recovery from limited measurements, quantum state tomography settings, etc.
-
A simple, but yet efficient, algorithm for Bipartite Correlation Clustering (Matlab)
In this code, we implement a simple, yet efficient, algorithm for the problem of Bipartite Correlation Clustering (BCC). Our algorithm solves a more generalized problem of maximizing a bilinear form, a specific instance of which is the BCC problem. In the demo included, we run our algorithm on a small movie lense dataset, in order to automatically extract useful clusters between users that have similar movie preferences.
-
ALgebraic PursuitS (ALPS) for sparse signal recovery (Matlab)
This software package implements the ALgebraic PursuitS class of methods for sparse signal recovery. ALPS framework includes some of the fastest Iterative Hard Thresholding (IHT) variants, utilizing optimal subspace exploration, cheap and adaptive step size selection and Nesterov-style accelerations. ALPS are also backed with strong theoretical guarantees, based on RIP assumptions in compressed sensing settings.
-
Matrix ALgebraic PursuitS (Matrix ALPS) for low rank recovery (Matlab)
This software package implements the Matrix ALgebraic PursuitS class of methods for low rank recovery. This set of problems includes the affine rank minimization, matrix completion and PCA settings. Similar to the vectors case, the Matrix ALPS framework includes some of the fastest Iterative Hard Thresholding (IHT) variants for low rank matrix reconstruction, utilizing optimal subspace exploration, cheap and adaptive step size selection and Nesterov-style accelerations. Matrix ALPS are also backed with strong theoretical guarantees, based on RIP assumptions in compressed sensing settings.
-
Matrix ALgebraic PursuitS (Matrix ALPS) for low rank + sparse recovery (Matlab)
This software package is the extension of the Matrix ALPS software package for the case of low rank and sparse recovery. Applications include background video subtraction and robust PCA, among others.
-
Self-Concordant OPTimization (SCOPT) for composite convex problems (Matlab)
SCOPT is a MATLAB implementation of the proximal gradient, proximal quasi-Newton, proximal Newton, and path-following interior-point algorithms for solving composite convex minimization problems involving self-concordant and self-concordant-like functions.
-
CLASH and Normed Pursuits: Hard thresholding with norm constraints (Matlab)
CLASH (Combinatorial selection and Least Absolute SHrinkage) and Normed Pursuits are new sparse signal approximation algorithm that leverages prior information beyond sparsity to obtain approximate solutions to the Lasso problem. These algorithms alters the selection process of Lasso algorithm by exploiting additional signal structure, dubbed as combinatorial sparsity model, and introduces approximate combinatorial selection with provable convergence guarantees.
-
Sparse projections onto the simplex (Matlab)
In this snippet of code, we compute sparse projections onto the simplex. Our approach is greedy, i.e., sequentially and greedily we construct the solution that $(i)$ minimizes the euclidean distance to an anchor given point, $(ii)$ "lives" on the simplex and, $(iii)$ is $k$-sparse. (The code is to be updated with some demo files).
-
Provable deterministic leverage scores sampling (Matlab)
Here, we explain in practice the curious empirical phenomenon: “Approximating a matrix by deterministically selecting a subset of its columns with the corresponding largest leverage scores results in a good low-rank matrix surrogate”. In this demo, we demonstrate empirically the performance of deterministic leverage score sampling, which many times matches or outperforms the state-of-the-art techniques.
-
Generalized Sparse Additive Models (GSPAM) with interactions in high-dimensions (Matlab)
This software package solves a d-dimensional GSPAM instance, where univariate and bivariate set of indices ($S_1$ and $S_2$, respectively) are unknowns. The code follows the steps indicated by the main algorithm, described in the conference paper.
-
Expanders and group sparse recovery (Matlab)
Proof of concept why expanders accelerate execution time of convex solvers for group sparse recovery. The problem setting is that of group sparse convex norm minimization over linear constraints. The experiments include both synthetic and real data settings.
-
Finding the M-PSK vector that maximizes a rank-deficient complex quadratic form (Matlab)
Given a rank-deficient PSD complex matrix as an input, computes the polynomial-sized set of candidate M-PSK solutions, among which the optimal M-PSK vector --that maximizes the rank-deficient quadratic form-- lies.
-
Multiway (tensor) compressed sensing for sparse and low rank tensors (Matlab)
In this contribution, we consider compressed sensing for sparse and low-rank tensors. More specifically, we consider low-rank tensors synthesized as sums of outer products of sparse loading vectors, and a special class of linear dimensionality-reducing transformations that reduce each mode individually. We prove interesting "oracle" properties showing that it is possible to identify the uncompressed sparse loadings directly from the compressed tensor data. This Matlab demo works as a proof of concept for the main ideas in the paper.