AI-OWLS
Open-source ML/AI algorithms research at Rice CS
PublicationsBlogposts
PI:
Anastasios Kyrillidis (Rice CS)
Students & Contributors:
Fangshuo (Jasper) Liao (Rice CS), Afroditi Kolomvaki (Rice CS), Ria Stevens (Rice CS), Wenyi (Barbara) Su (Rice CS), Mahtab Alizadeh Vandchali (Rice CS), Evan Dramko (Rice CS), Ziyun Guang (Rice CS), Michael Menezes (Rice CS), Jucheng Shen (Rice CS)
Blogposts
-
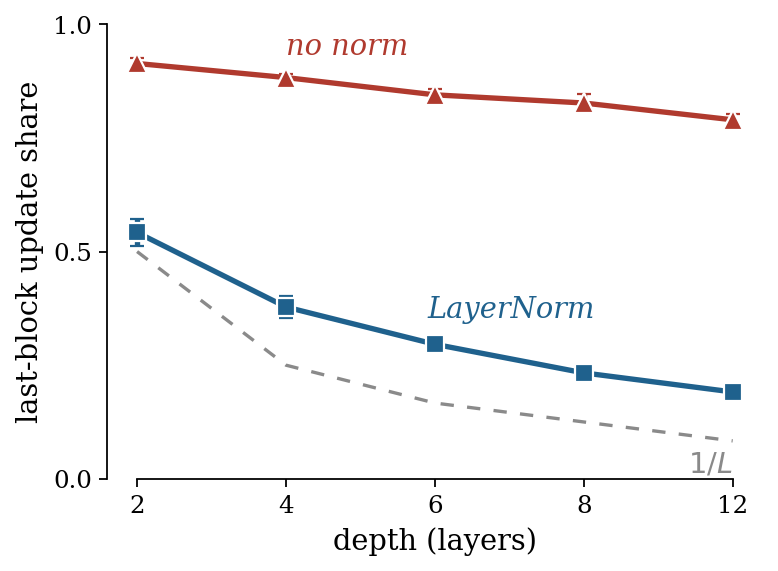 Which Layer Runs the Program?
A ground-truthed, causal complement to the “where computation lives” question. In collaboration with Microsoft Research.
Which Layer Runs the Program?
A ground-truthed, causal complement to the “where computation lives” question. In collaboration with Microsoft Research.
-
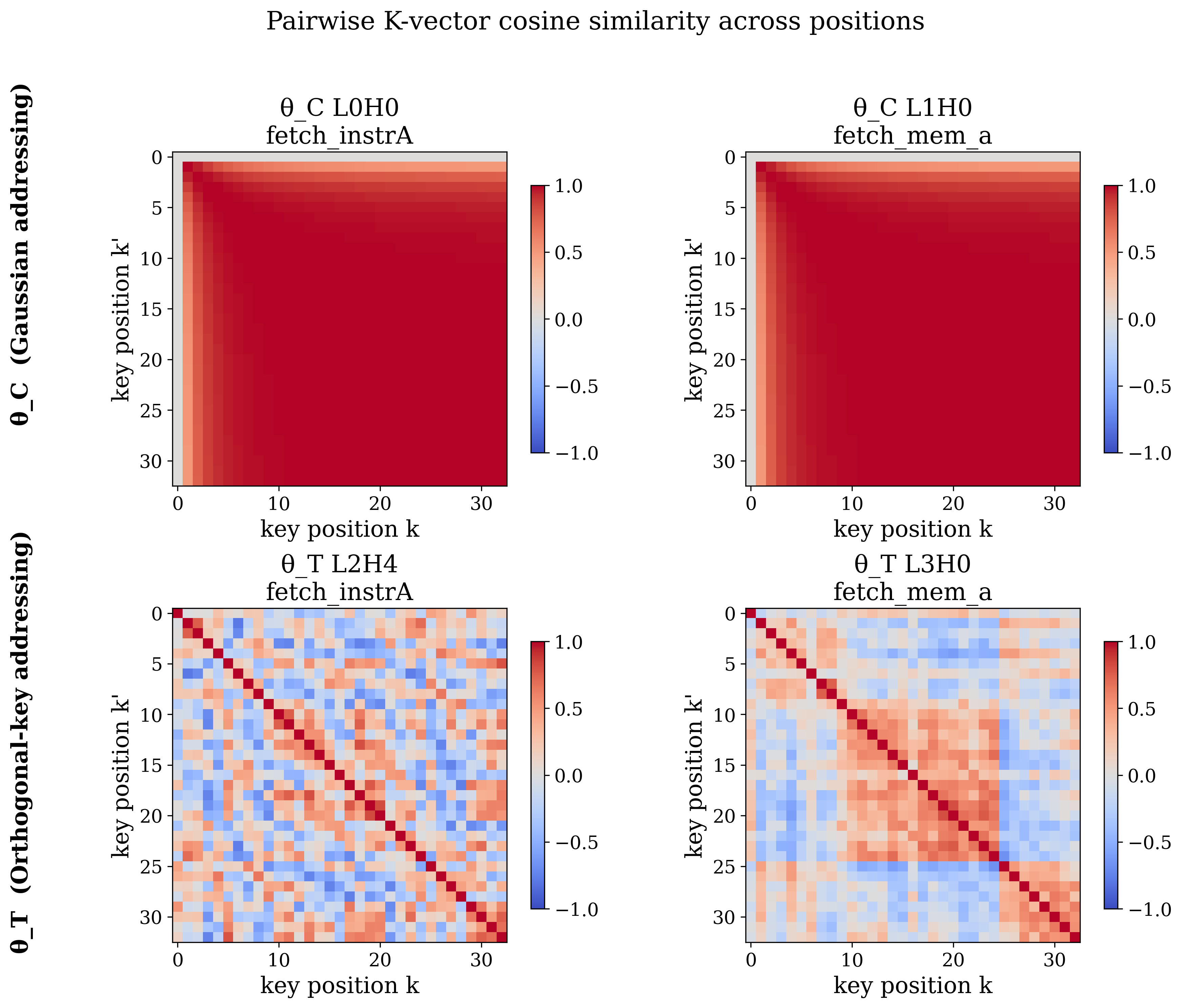 Can We Train a Computer? Two Ways to Point at a Memory
A ground-truthed case for mechanistic probes over weight-space interpolation. In collaboration with Microsoft Research.
Can We Train a Computer? Two Ways to Point at a Memory
A ground-truthed case for mechanistic probes over weight-space interpolation. In collaboration with Microsoft Research.
-
 Which Valley, and How Deep: Training Neural Atomic Relaxation at a Fraction of the Memory
From the OptimaLab (Rice CS); one wrapper over ADAPT, eSEN-OC25 & GemNet-OC.
Which Valley, and How Deep: Training Neural Atomic Relaxation at a Fraction of the Memory
From the OptimaLab (Rice CS); one wrapper over ADAPT, eSEN-OC25 & GemNet-OC.
-
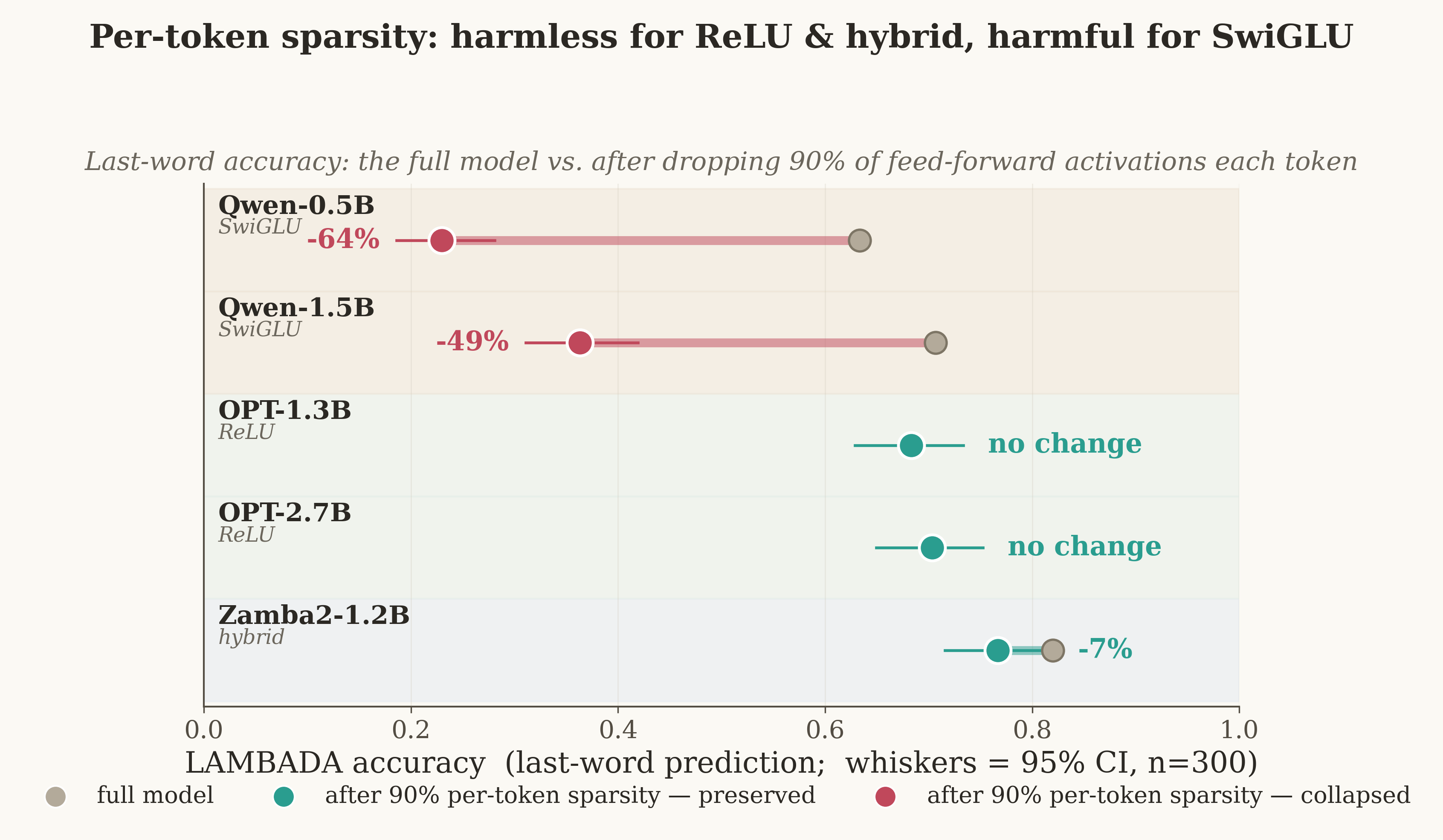 Two Ways to Slim a Model: Remember vs Recompute
Building on Michael Menezes’s GHOST (Rice CS).
Two Ways to Slim a Model: Remember vs Recompute
Building on Michael Menezes’s GHOST (Rice CS).
-
 One Rank at a Time: Cascading Error Dynamics in Sequential Learning
With Mahtab Alizadeh Vandchali and Fangshuo (Jasper) Liao (Rice CS).
One Rank at a Time: Cascading Error Dynamics in Sequential Learning
With Mahtab Alizadeh Vandchali and Fangshuo (Jasper) Liao (Rice CS).
-
 One Model, Two Roles: Emergent Specialization in a Shared Recurrent Transformer
With Jucheng Shen and Barbara Su (Rice CS).
One Model, Two Roles: Emergent Specialization in a Shared Recurrent Transformer
With Jucheng Shen and Barbara Su (Rice CS).
-
 From PCA to LoRA: Why Fine-Tuning Could Have Been Parallel All Along
With Barbara Su, Fangshuo (Jasper) Liao (Rice CS).
From PCA to LoRA: Why Fine-Tuning Could Have Been Parallel All Along
With Barbara Su, Fangshuo (Jasper) Liao (Rice CS).
-
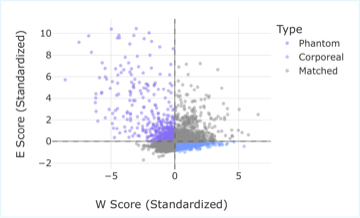 GHOST: pruning Mamba2 by what each channel does
With Michael Menezes (Rice CS).
GHOST: pruning Mamba2 by what each channel does
With Michael Menezes (Rice CS).
-
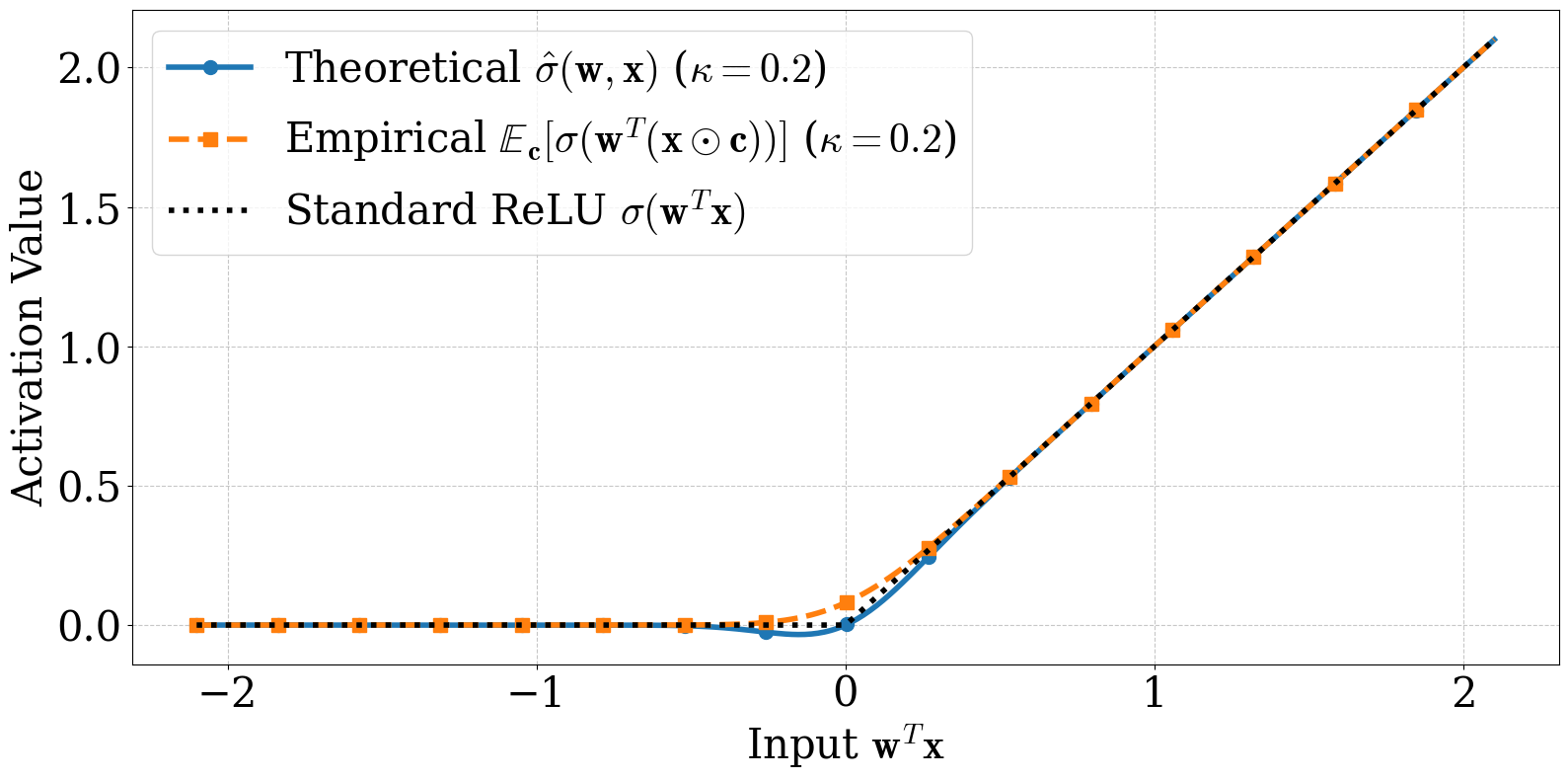 How a little Gaussian dust changes how a network learns
With Afroditi Kolomvaki, Fangshuo (Jasper) Liao, Evan Dramko, Ziyun Guang (Rice CS).
How a little Gaussian dust changes how a network learns
With Afroditi Kolomvaki, Fangshuo (Jasper) Liao, Evan Dramko, Ziyun Guang (Rice CS).
-
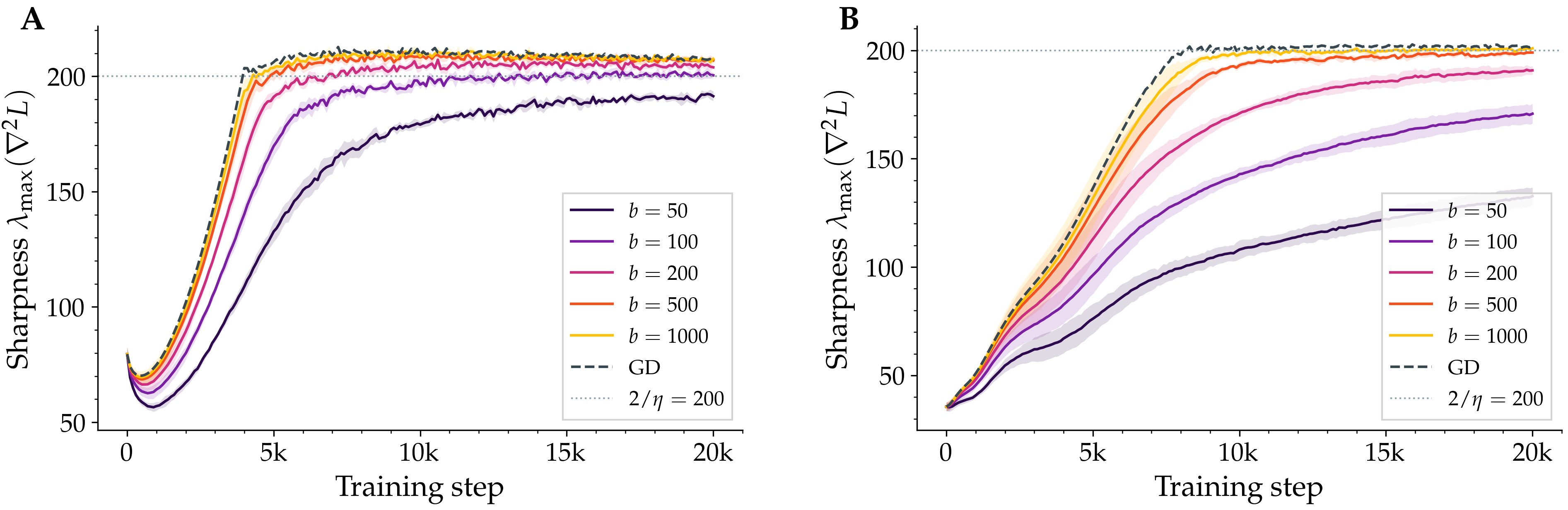 Why Stochastic Gradient Descent Stops Just Short of the Edge
With Fangshuo (Jasper) Liao, Afroditi Kolomvaki (Rice CS).
Why Stochastic Gradient Descent Stops Just Short of the Edge
With Fangshuo (Jasper) Liao, Afroditi Kolomvaki (Rice CS).
-
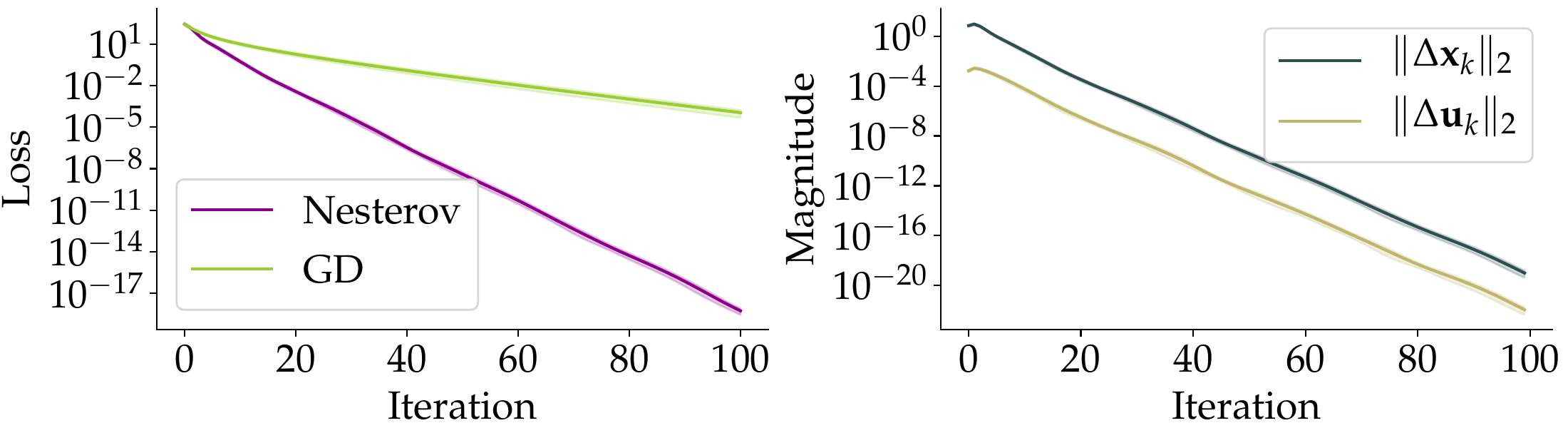 Provable Acceleration of Nesterov's Momentum for Deep ReLU Networks
With Fangshuo (Jasper) Liao (Rice CS).
Provable Acceleration of Nesterov's Momentum for Deep ReLU Networks
With Fangshuo (Jasper) Liao (Rice CS).
-
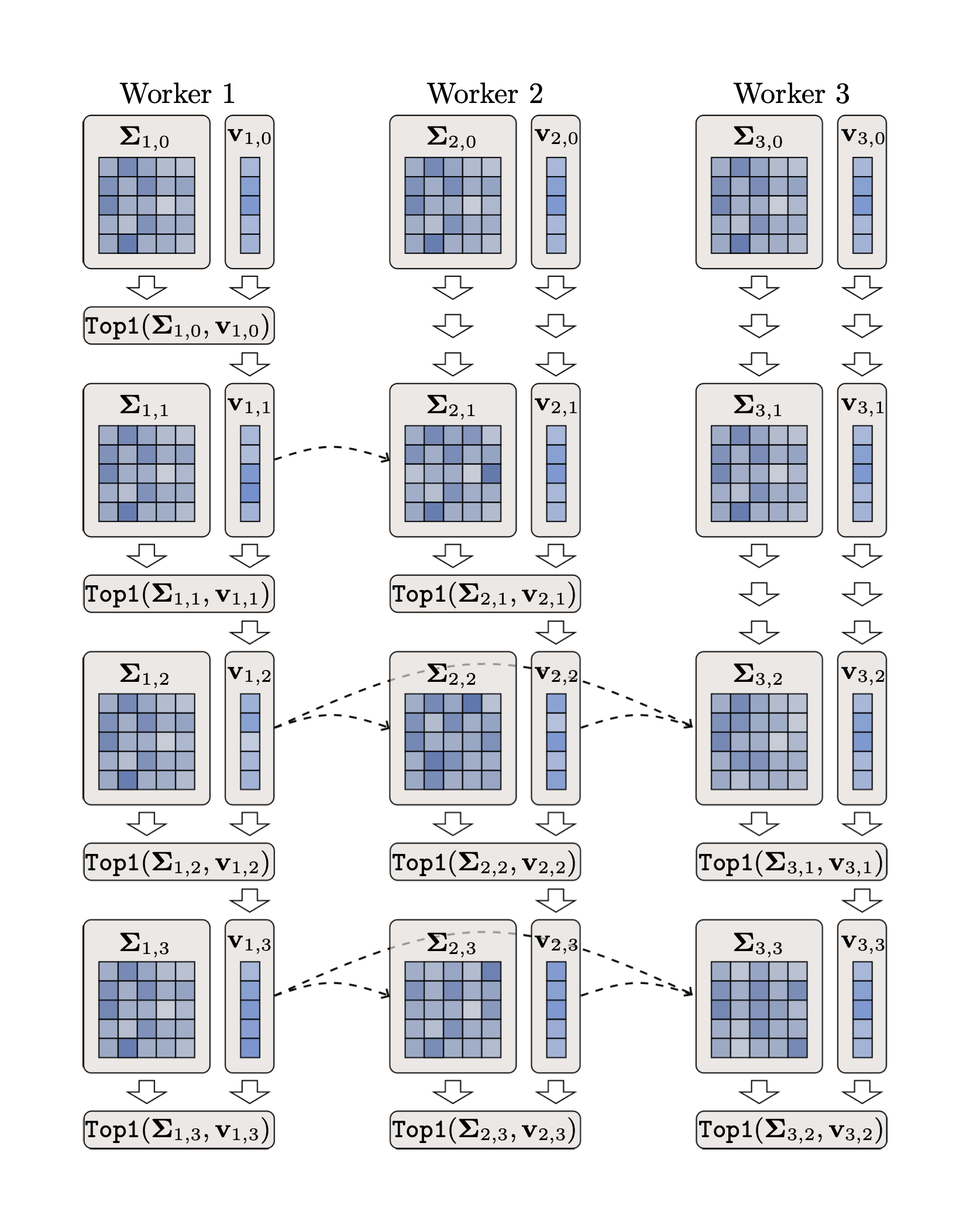 Provable Model-Parallel Distributed Principal Component Analysis with Parallel Deflation
With Fangshuo (Jasper) Liao, Wenyi Su (Rice CS).
Provable Model-Parallel Distributed Principal Component Analysis with Parallel Deflation
With Fangshuo (Jasper) Liao, Wenyi Su (Rice CS).